Google File System: Chunk and Conquer


The Google File System is a widely studied distributed file system. Its ability to provide a scalabily and fault tolerance on inexpensive commodity hardware made it a platform of choice within Google. The design goals of this file system was similar to its predecessors - performance, scalability, reliability and availability with a spin. It was driven by observation of Google's application workloads and present and future technological environment. In this blog we aim to give a background and a high level overview of the design ideas used in the paper. But why was a new distributed file system needed at Google in the first place?
Some of the key observations that influenced design were:
- Component failures are the norm and not the exception - especially when using inexpensive commodity hardware. This means that a monitoring, detection, fault-tolerant and recovery mechanism must be instituted.
- Files are large needing some design and parameter values to be revisited. Small files can be supported but need not be optimized for.
- Read workloads are broadly of 2 types - large streaming reads and small random reads. Applications can batch random reads to be more performant
- Write workloads are largely append and as such become the focus of performance optimization and atomicity guarantees.
- Codesigning applications and file system API increases flexibility such as a relaxed consistency model and reduced synchronization requirements between clients for file append.
- Target applications need high sustained bandwidth while latency requirements are not so stringent
Interface
GFS provides a familiar file system interface with directory hierarchies although API itself differs from POSIX. The operations supported are
| 1. Create | 2. Delete | 3. Open |
| 4. Close | 5. Read | 6. Write |
| 7. Snapshot | 8. Record append |
The last 2 are unique. Snapshot creates a low cost copy of a file or directory tree. Record append allows multiple clients to append to the same file concurrently guaranteeing atomicity without additional locking.
Architecture
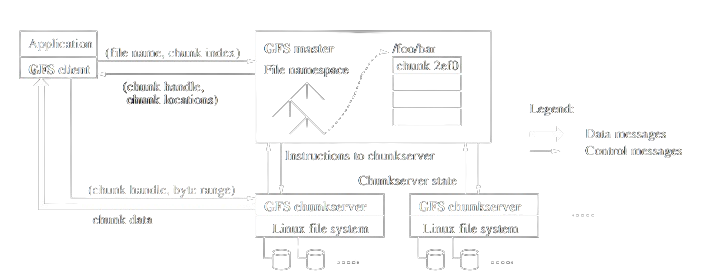
A GFS cluster consists of a single master (its not a SPOF - a fact we'll discuss later) and multiple chunkservers. Files are divided into fixed sized chunks and stored on chunkservers. For better reliability, they are replicated across multiple chunkservers as specified by the replication factor.
As shown in the architecture diagram, all file system metadata is maintained in-memory by the master. It is also responsible for controlling and collecting state of chunkservers via a heartbeat message sent out at regular intervals. Additionally the master coordinates system-wide activities (again we'll discuss this a bit later)
In order to prevent master from becoming a bottleneck:
- Chunk size is kept large (64MB). This reduces need for client-master interaction as well as reduces memory requirements for the master.
- Clients use metadata caching which removes need for interacting with master atleast till the cache is invalidated.
Now the question is what is this metadata?
Metadata
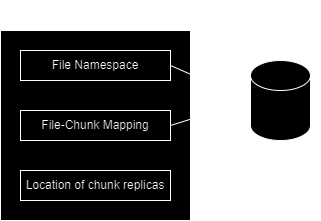
- All metadata is in-memory for master operations to be fast. Of course this could be a scalability issue but it keeps the overall system simple and responsive
- The master doesn't persistently store mapping between chunks and chunkservers instead choosing to poll this information from chunkservers via the heartbeat messages. Thus master is always in sync with what chunkservers are in the cluster.
- The operation log is critical to maintain consistency in the system. It is also useful for crash recovery (checkpointing can be used to reduce overhead of crash recovery).
Consistency Model
GFS has a relaxed consistency model. Before understanding the "relaxed" aspect, lets just examine what consistency means for the system
| Write | Record Append | |
|---|---|---|
| Serial success | defined | defined; interspersed with inconsistent |
| Concurrent success | consistent but undefined | defined; interspersed with inconsistent |
| Failure | inconsistent |
💡Note:
| Consistent | A file region is consistent if all clients will see the same data regardless of the replica they read from |
| Defined | A file region is defined if after a data mutation, it is consistent and all clients will see what the mutation writes in its entirety |
Of course component failures can still hamper system integrity but this is handled by handshakes between master and chunkservers as well as checksumming to detect data corruption. Even in cases where all replicas fail for a particular chunk, the application still receives clear errors rather than corrupt data.
A very pertinent point that the paper drives is that appending is far more efficient and resilient to application failures than random writes.
System Interaction
The system is designed to minimize client-master interactions. The paper discusses several mechanisms that allow for this design objective.
1. Lease and Mutation Order
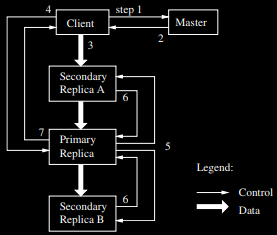
From the paper
Leases are used to maintain a consistent mutation order across replicas. The master grants an expirable chunk lease to one of the replicas called primary. The primary decides a serial order for mutations and the other replicas have to follow this order. Even though lease is expirable, it can easily be extended by the primary by piggybacking an extension request on the heartbeat messages.
In case the primary goes offline, master can grant lease to one of the replicas after the old lease expires.
2. Data Flow
Data and control flows are decoupled. In addition to preventing a bottleneck at the master, it also serves the following goals:
- Fully utilize each machine's network bandwidth - data is pushed linearly along chain of chunkservers allowing each machine's full bandwidth to be undividedly used to transfer data
- Avoid network bottlenecks - each machine pushes data to the "closest" machine in the network that has not received it. Distances can be accurately estimated from IP addresses
- Minimize the latency to push through all the data - as soon as a chunkserver receives some data it starts forwarding immediately over full duplex links
3. Atomic Record Appends
In a record append, the client specifies only the data. GFS guarantees data is written atleast once atomically at an offset of GFS's choosing and returns that same offset to the client. This mechanism eliminates the need for synchronization between clients which would inevitably fall on the master. The separation of data and control flows helps here as well!
4. Snapshot
The snapshot operation makes a low effort copy of a file or directory. Why low effort? Because it copies chunks lazily only when chunks in the original are modified (copy-on-write). Now snapshot reduces the involvement of master because the master doesn't do the chunk creation process from scratch (identifying chunkservers for placement and the works). All it does is that it revokes any outstanding leases on the file chunks and increments the associated reference counts. Now when a "snapshotted" chunk is sought to be modified, the master notifies each of the replicas that they need to create a copy of the chunk. Once copies are made, master grants lease to one of the chunkservers on the new chunk and replies to the client with the necessary metadata. In this way control signals passing through the master are minimized.
Master Operation
The master is responsible for all control signaling. Lets just run through the responsibilities of the master and how they play into tying the system together.
1. Namespace management and locking
Different master operations take differing amounts of time and these operations may not interact with the same parts of the namespace. In a bid to keep the system agile, each node in the namespace tree (file or directory) has an associated read-write lock. With this scheme, concurrent mutations can be made in the same directory since a write lock needs to be acquired only on the terminal end of the path. Lock acquisition too follows an order that avoids deadlocks.
2. Replica Placement
The master must distribute chunks so that it meets the twin objectives of:
- Data reliability and availability
- Maximize network bandwidth utilization
This can be done by spreading chunks across machine as well as across racks. There will be some tradeoffs for write performance across racks but the benefits outweight the cost.
3. Creation, Re-replication and rebalancing
Master chooses to place replicas based on the following:
- Place replicas on chunkservers with below average disk utilization - load balancing for both storage and network
- Limit number of recent creations on chunkservers - new chunkservers that join the cluser are not swamped by heavy write traffic
- Spread replicas across racks - in case of rack failures, there's a way to recover data
Re-replication happens when number of replicas for a chunk falls below the replication factor defined by the user.
Rebalancing happens periodically to ensure good disk space and load balancing.
4. Garbage Collection
Storage place is reclaimed lazily on file deletion. This makes the system simpler and more reliable. However, additional work is needed to support situations when storage is tight. The benefit is that chunk metadata is modified on the master without needing immediate deletion from the chunkserver replicas. User could retrieve files that are deleted as well as tune the interval after which chunks are physically deleted from the chunkservers.
5. Stale Replica Detection
How could the master tell if a replica is stale? This is where the role of chunk version number becomes important. When a mutation is initiated, the chunk version number is increased across replicas as well as in the master metadata (and operation log) in a persistent state. When there is a mismatch in the version numbers, appropriate corrective measures are taken on either bringing the master up to speed or removing the stale replica in the regular garbage collection. As an additional safeguard, the master also communicates the version number to the client which the client can validate while communicating with the chunkserver.
Fault Tolerance and Diagnosis
As the designers put it - Component failures are the norm and not the exception. This section is primarily to go over some design features that address this.
1. High availability
The overall system is kept highly available via:
- Fast recovery: Master as well as the chunkservers can restore their state and start in a couple of seconds. Previously, checkpointing was discussed as a means to reduce crash recovery time.
- Chunk replication: Each chunk is replicated across chunkservers and racks by a user specified replication factor.
- Master replication: This was the aha moment for me! Turns out to prevent master from becoming the single point of failure in the cluster, the operation log and checkpoints are replicated on multiple machines. On master failure or corruption, a new machine starts the "master" process and life goes on.
2. Data Integrity
Each chunkserver uses checksumming to detect corruption of data. Chunks are broken into 64KB blocks and associated with a 32 bit checksum. If there's a mismatch, chunkserver returns an error to the client and reports this to the master. The client reads from a different replica while the master clones the chunk from another replica. Once the new replica is set up, the master instructs our faulty chunkserver to delete its replica.
3. Diagnostic Tools
GFS servers generate diagnostic logs that record events such as chunkservers joining and leaving the cluster, master going down as well as RPC requests and replies. These logs can be useful traces to diagnose problems, measure performance and loading on the system.
Conclusion
GFS significantly contributed to Google's storage capabilities, setting a precedent for distributed file systems with its innovative architecture and system design. At a time where there was a general move towards decentralized storage systems (Oceanstore, PAST), GFS kept it simple, stupid by opting for a master-worker framework. GFS was eventually replaced by Colossus which uses BigTable, a distributed database that is much more scalable. But the simplicity of the design is just something I admire and I'm sure you do too now.