Langchain Unchained: From Prompt to Possibilities
Redefining LLM interactions with LangChain


Introduction
Ever since, OpenAI release ChatGPT in 2022, interest in LLMs has skyrocketed. Here was a model capable of answering questions, summarizing, rewording and generating content and much more. The models themselves are so powerful that you might ask - why do we need a new framework like LangChain? What new powers does it give us?
There's 2 reasons why LangChain is needed.
- It makes the mode of interaction with LLMs more formally extensible.
- We can chain together different components to create more advanced use cases around LLMs.
Ergo, lets dive right into this framework.
There are 4 major components that LangChain provides us with:
- Prompt Templates
- LLMs
- Memory
- Agents
In the next parts, we'll go over these components one by one.
Installing LangChain
pip install langchain
.
1. Prompt Templates
To ask the right question is already half the solution of a problem
Carl Jung
A prompt is composed of multiple parts:
- Instructions: Tell the model what to do - how to use external information, what to do with the query, how to construct the output, etc
- External Information(context): Add knowledge to the model. While could be part of the prompt, could also come from a vector database, or pulled in via tools
- User input(query): The query input to the system
While it isn't necessary for a prompt to contain all these components, a good prompt will contain these components to provide clarity to the LLM and prevent any hallucinations
Prompt template classes in LangChain are designed to incorporate these components in a simpler, more extensible manner. The simplest among these is the PromptTemplate class. You can read more about this class here
Why not simply use formatted strings you may ask? Would they work just as well? And you would be right here mostly. The reason for using Langchain's PromptTemplate is to formalize the process of prompt construction - add multiple parameters, validate them, etc and build prompts with an object-oriented approach.
Another notable class is the FewShotPromptTemplate which allows our model to develop an understanding of what we're asking it to do by providing a set of examples containing model input-outputs. More details on the api here. An interesting feature worth discussing is the ability to limit the number of examples by using the example_selector parameter. Use the example_selector module to choose an appropriate example selector.
2. LLMs
The real problem is not whether machines think but whether men do
BF Skinner
Large Language Models (LLMs) are perhaps the central component of LangChain. LangChain doesn't serve its own LLMs. Rather it simply exposes an interface for interacting with many different LLMs. Check out the list of LLM integrations here
3. Memory
Who lies forgotten, disappears from the future
LLMs are stateless. But that doesn't make them too useful does it? In several situations, we do want to retain context of previous interactions. This necessitates the requirement of a "conversational memory" - a fancy way of just passing the conversation history to the model. In LangChain, conversational memory is built on top of the ConversationChain class.
The template of the conversation chain has 2 input variables:
- history
- input
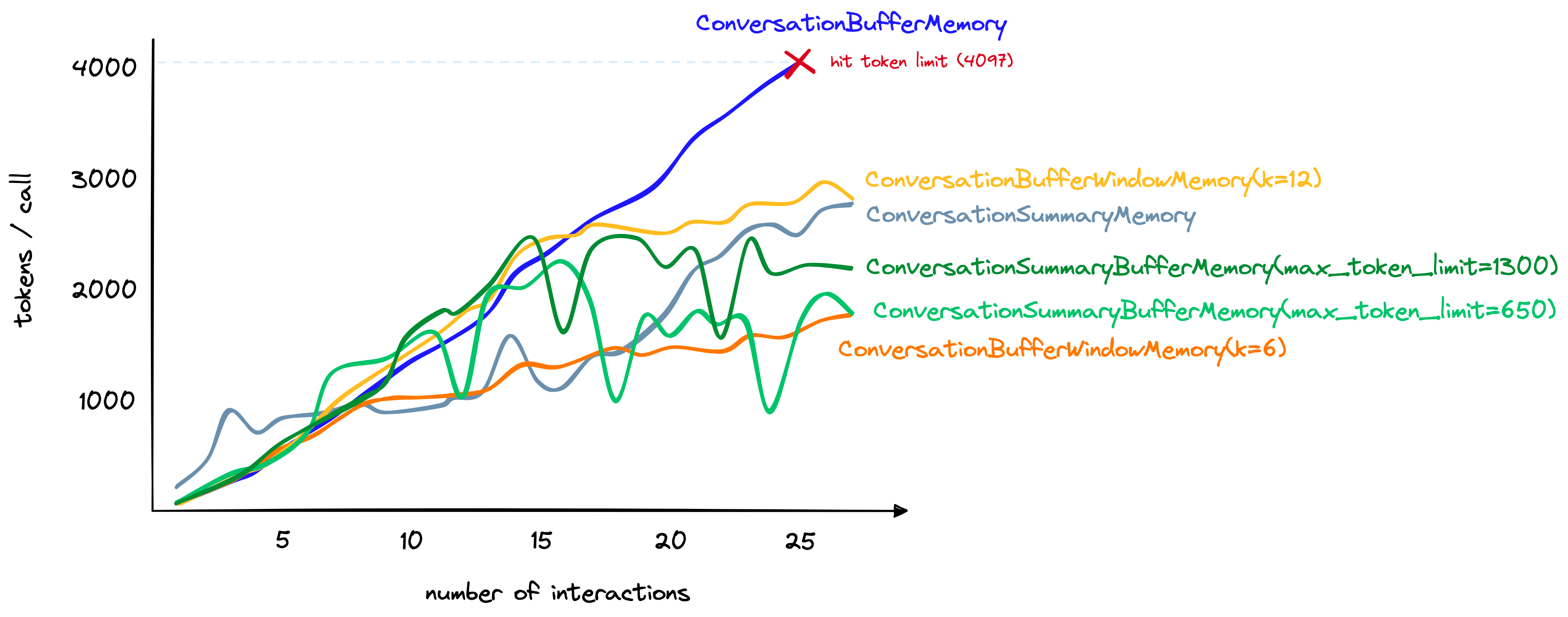
Instantiating the chain needs an LLM and a type of memory. Whats a "type" of memory and why is it needed in the first place? Ah that brings us to a very fundamental nature of the state of the art large language models today - context window and token limit. Basically as the size of the prompt increases, our model becomes not only becomes costlier to run but also more prone to hallucinate. Further, even the largest model are capped at a certain number of tokens so we can't feed an endless stream of tokens.
The types of memory address this challenge in different ways and the choice of which one depends entirely on our use case.
ConversationBufferMemory
Entire conversation is passed to the history parameter
| Pros | Cons |
|---|---|
| gives the LLM the maximum amount of information | slows response times and increases costs |
| simple | easily hit the LLM token limit |
ConversationSummaryMemory
Summarizes the conversation history before it is passed to the history parameter.
| Pros | Cons |
|---|---|
| shortens the number of tokens for long conversations | higher token usage for smaller conversations |
| enables longer conversations | relies on the summarization ability of the summarization LLM |
| simple to understand | costs increase as tokens are used for the summarization LLM |
ConversationBufferWindowMemory
We keep a given number of past interactions before forgetting them.
| Pros | Cons |
|---|---|
| limits number of tokens being used | distant conversations are forgotten |
ConversationSummaryBufferMemory
Summarizes the earliest conversations and maintains a max_token_limit for the most recent tokens - combines the best and worst of conversation summary and conversation buffer window memories.
| Pros | Cons |
|---|---|
| remember distant interactions | summarizer increases token count for shorter conversations |
| buffer prevents us from missing information from the most recent interactions | storing the raw interactions increases token count |
4. Agents
All for one and one for all, united we stand, divided we fall.
Alexandre Dumas
Large Language Models are powerful yet struggle in abilities such as math, logic and search. This is where the role of agents and tools comes in. Agents can supercharge our LLMs with several abilities - perform math, execute scripts, query databases, make API calls and much more.

Using agents entails 3 critical pieces:
- LLM itself
- Tool that will be used
- Agent to control the 2
There are several prebuilt tools. You can find them here. Furthermore, we can also create custom tools with the BaseTool class.
Agent Types
💡Note: ReAct refers to the cycle of Reasoning and Action that the LLM takes to arrive at an answer.
We have several kinds of tools based on the objective of our tooling.
- Zero Shot ReAct: Agent considers one single interaction and will have no memory
- Conversational ReAct: Agent can interact with the same tools but retains memory so we can ask follow-up questions based on its responses
- ReAct Docstore: Built for information search and lookup using a LangChain docstore.
- Self-Ask With Search: First choice when connecting an LLM with a search engine. The LLM will perform searches and ask follow up questions as often as required to arrive at the final answer.
For details on this refer here and here
Conclusion
So now we have a high level overview of LangChain. LangChain is an extremely powerful framework and due to its open source nature, it is rapidly evolving. Build powerful projects and change the world with it!
References
- Langchain AI Handbook Pinecone. Available at: https://www.pinecone.io/learn/series/langchain/ (Accessed: 04 January 2024).
- Langchain Docs. Available at: https://python.langchain.com/docs/get_started (Accessed: 04 January 2024).