MapReduce: Distributed Computing For All

Computer science is the science of abstractions. So much simply happens because a group of developers somewhere set out to abstract out a complex process for developers everywhere. But there's still a balancing act. Too many abstractions introduces too many overheads - too few and we're reinventing the wheel. One such brilliant abstraction - rather a programming model set a new precedent for frameworks that enabled distributed computing and completely transformed how Google performed distributed indexing. This was MapReduce, introduced by Jeff Dean and Sanjay Ghemawat in 2004 which sought the following:
- Automatic parallelization
- Fault tolerance against machine failures, network partitioning
- Network and disk optimization for commodity machines
Their solution banked on the assumptions that commodity networking infrastructure is used, failures are common, storage is cheap, file system is replicated and input can be split.
Core Idea
KISS - Keep it Simple, Stupid
The core idea behind MapReduce is simple. It allows programmers to perform computation on enormous amounts of key value pairs, hiding the gory details of parallelization, load distribution and fault tolerance. Just as a chef maintains mise en place - prepping ingredients before combining them, MapReduce does this by dividing the computation into 2 stages:
- A map operation on key-value pairs to produce intermediate key-values.
(k1,v1)→list(k2,v2) - A reduce operation to combine the data produced in stage 1.
(k2, list(v2))→list(v2)
Does this restrict the flexibility of the programmer to manipulate data? Sure it does. It dwells in the design space which empowers the framework while exacting a small price from the programmer. The other option was to manage task synchronization, race conditions on shared variables, manage loads across clusters and recompute tasks on machine failures - clearly a lot to do! Given the wide variety that are expressible in the form of the above two operations, its not a bad price to pay. Moreover, the ability to scale seamlessly to thousands of machines made it the force behind Google search for nearly a decade. Lets examine how this works in greater detail.
Examples
We reject kings, presidents and voting. We believe in rough consensus and running code
Dave Clark
Word Counter

Inverted Index

Distributed Sort

And more! Lot of generalizability in the model.
Architecture
If 1000 solutions exist, no great one does
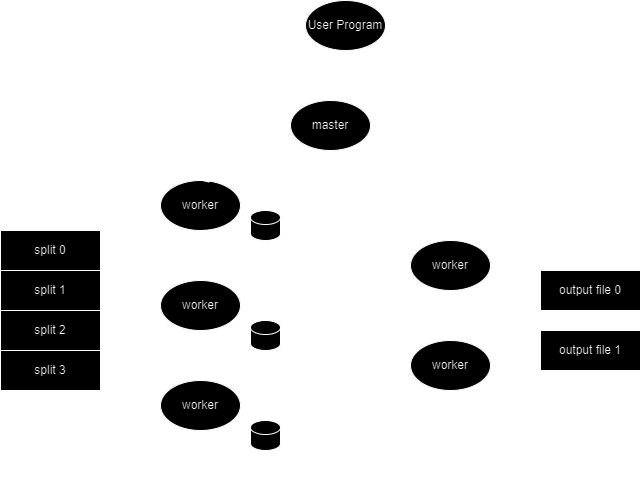
Here's where our GFS knowledge will come in handy. The following is the flow of the MapReduce operation:
- The MapReduce library in the user program splits the input file into
M16-64MB chunks (can you think why the upper bound of 64?). It then proceeds to fire copies of the program on the cluster - One copy is different - the master. The others are labelled workers and pick up tasks assigned to them by the master task. There are
Mmap andRreduce tasks. The master tries to assign the map tasks such that the map workers and the shards (on GFS!! Thats why the 64MB bound) are collocated. This way network IO can be reduced. - The map worker reads its assigned chunk and passes the key-value pairs to the map function. The intermediate key-value pairs are buffered in memory.
- These buffered key-value pairs are periodically written to local disk after being partitioned into R regions by the partitioning function. The location of these regions are communicated to the master which will forward them to the reduce workers.
- The reduce worker will read these intermediate outputs, sort them on intermediate keys (ordering guarantee within a partition!) and iterates over them passing them through the
reducefunction. The output of reduce is appended to the final output file for that partition - Once the map and reduce tasks conclude, the master wakes up the user program and returns to user code execution.
Sometimes a combiner task is added between the map and reduce tasks. This is basically to ameliorate the effect of skewed data with hotspots. The only difference typically between the reduce and the combiner stage is that combiner will write to local disk whereas reducer will write to the final output file.
eg. Count the occurence of 'the' in our dataset.
Master Data Structures
The master stores the following data structures:
- State(idle/in-progress/completed) of map or reduce task and identity of the worker machine
- Locations and sizes of the intermediate key-value partitions from the
mapstage
Fault Tolerance
Be wary then; best safety lies in fear
Laertes
Worker Failures
| Task | In-progress | Complete |
|---|---|---|
| Map | Task is reset to idle state and becomes eligible for rescheduling | Task is reset to idle state and becomes eligible for rescheduling since local disks become unreachable |
| Reduce | Task is reset to idle state and becomes eligible for rescheduling | Task does not need re-execution because output is on the global file system |
Worker failures assume that the output is idempotent and deterministic so retries will have well-defined outcomes. Furthermore, the authors introduce the concept of backup tasks. These tasks get scheduled by the master because not all machines will finish their tasks even on equal loading due to machine specific reasons (bad disk, too many running processes, etc). If some workers get freed up, the master may schedule backup execution of in-progress tasks. This way if either of the workers completes, the master can mark task as completed and the system becomes agnostic to one bad link in the chain. Moreover, after a specific number of retries on a record, the master might just abandon that record instead of looping indefinitely or aborting the entire operation.
Master Failures
Although a complex mechanism like checkpointing and the associated paraphernalia could have been implemented, the authors simply let the MapReduce computation get aborted allowing clients to retry the MapReduce operation.
Conclusion
Until MapReduce and GFS was introduced, Google's systems used a piece of software written by Page and Brin called BigFiles (or BugFiles as was colloquially known). The indexing code would take days to finish and would restart from the beginning if it encountered errors. With MapReduce and other enhancements, Jeff and Sanjay united the fleet of computers at Google's disposal. The indexing code became simpler, smaller and easier to understand as well as more resilient to machine and network hitches. It's no surprise then that this system remained a cornerstone of Google's infrastructure for almost ten years before it was eventually phased out.
References
If I have seen further than others, it is by standing upon the shoulders of giants
Sir Isaac Newton
Jeffrey Dean and Sanjay Ghemawat. 2008. MapReduce: simplified data processing on large clusters. Commun. ACM 51, 1 (January 2008), 107–113. https://doi.org/10.1145/1327452.1327492
Somers, J. (2018) The friendship that made google huge, The New Yorker. Available at: https://www.newyorker.com/magazine/2018/12/10/the-friendship-that-made-google-huge (Accessed: 09 February 2024).