One-For-All: Building a Unified Query Analysis Layer
To ask the right question is already half the solution to a problem.


Retrieval Augmented Generation is becoming ubiquitous with LLM applications now. As larger context lengths become prohibitive in terms of costs, we'll see more companies turning to well-maintained knowledge bases supported with smaller models to answer user queries. But the unsuspecting user is never needed to know the embedding models used for retrieval and the final model that generates the answer. How then can we best support the unstructured nature of their queries and enable our RAG system to provide the best possible response? Answer - an intervening query analysis layer.
The promise of the query analysis layer is simple - augment and split queries so that our knowledge base can be queried in all sorts of ways to provide the final answer.
Decomposition
Humans often substitute a really difficult question with several simpler ones. Decomposition does exactly this for the LLM. Instead of asking one really difficult question, ask multiple easier ones. This method is very well illustrated in this paper
Expansion
Since the user is never needed to know the characteristics of the embedding model we use for our knowledge base, they might not ask the most optimal query. To work around this, why not rephrase in a multitude of ways and check? Query2Doc does this and more to improve retrieval accuracy
HyDE
I call this the fake it till you make it approach. Hypothetical Document Embeddings or HyDE pretends the LLM already knows the answer and allows it to hallucinate. Next it prepends the original query a number of times to the initial "answer" and uses this result to retrieve relevant documents from the vector store.
Step Back Prompting
The closer you are, the less you see.
It pays to ask a more general question before diving into specifics. This is what step back prompting basically does.
Query Analysis Layer
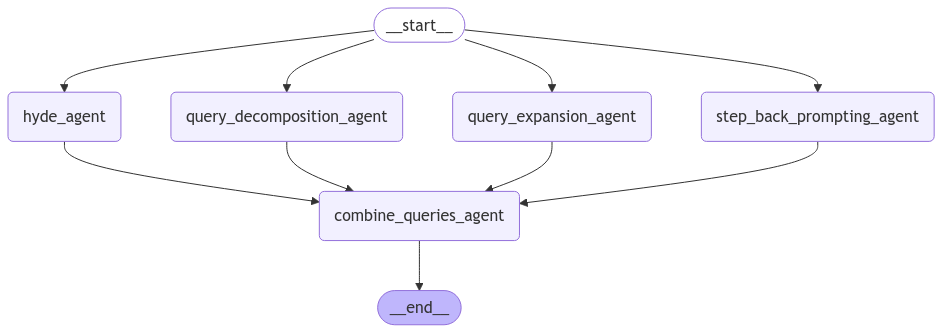
The query analysis layer combines all these techniques into one MapReduce style layer. The different parallel paths recreate different techniques and finally we combine queries and send to the retrieval pipeline. I've attached the code to recreate the pipeline below.
I'm currently using GPT-4o but any LLM can be substituted in its place to create the variants of the query from this layer.
We posed a question What is the population of the capital city of the country where Bastille Prison is located? for which we obtained the following responses from the combine_queries_agent:
| Decomposition | Expansion | HyDE | Step Back Prompting |
|---|---|---|---|
| What is the capital of the country where Bastille Prison is located? | What is the population of the capital city of the country where Bastille Prison is situated? | What is the population of the capital of the country where Bastille Prison is located? (x3) The Bastille Prison, a symbol of royal authority in the center of Paris.... | What is the capital of the country where Bastille Prison is located? |
| What is the population of that capital city? | What is the number of people living in the capital of the country where Bastille Prison can be found? | What is the population of the capital of the country where Bastille Prison is located? | |
| How many inhabitants are there in the capital of the country where Bastille Prison is located? |
Next Steps
With our query analyzer layer in place, we now have the means to restructure user prompts for better retrieval accuracies. However, there are 2 pitfalls to this approach-latency and cost. Because of an intermediate layer that also consumes tokens, both will rise leading to suboptimality especially when real-time answers are needed. We can reduce costs by monitoring response quality from each branch over a period of time and cut out a technique that leads to negligible improvements. Reducing latency is more challenging and could be addressed by a auto-suggest layer that is more tuned to the quirks of the embedding model that align user queries or could be achieved by limiting the number of query variants in the analysis layer.