PipeDream: The Dreamweaver of Distributed Training


The authors of PipeDream set out to solve an ambitious problem - how do you train a colossal model on a distributed cluster? Dividing the vast dataset required to support model training is certainly needed. With huge models, we may even need to segment the model itself into various stages. But how do we do both, while maintaining a high degree of utilization of compute resources? This is the quandary that PipeDream sought to solve efficiently. Lets briefly skim over the motivation behind the system.
Limitations of intra-batch parallelism
Know thy enemy and know yourself; in a hundred battles, you will never be defeated.
Sun Tzu
Intra-batch parallelism entails a single iteration is split across available workers. We can have the following flavours of this form of parallelism
Data Parallelism
Inputs are partitioned across workers. Workers have their own version of weights and a means to synchronize weights with other workers. Data parallelism has the following pitfalls:
- Communication overheads that effectively negate adding more workers.
- Memory footprint of replicating model on all machines becomes significant with increasing model sizing and sometimes might not even be feasible.
Model Parallelism
The model is partitioned across multiple workers. Workers evaluate and update only a subset of model parameters and communicate their (intermediate) outputs or gradients to the upstream or downstream workers. This suffers from:
- Under-utilization of compute.
- Partitioning becomes the responsibility of the programmer leading to non-generalizable solutions
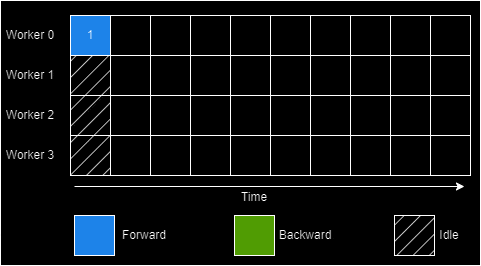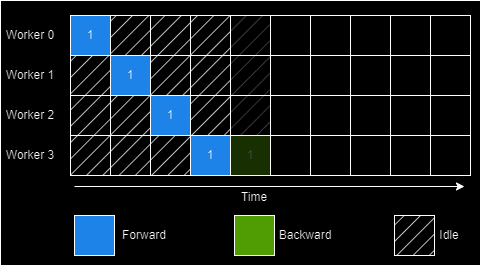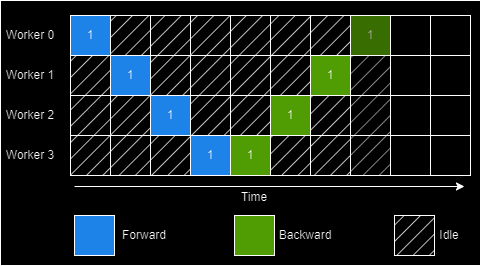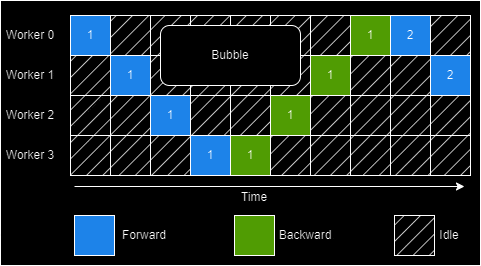
Hybrid Parallelism
Parts of the model that are less compute hungry are replicated across workers (eg. some convolutional layers) and the more compute hungry layers (eg. dense layers) aren't. While this leads to reduction in some communication overheads it still leaves much of the performance on the table (not to mention bottlenecks!).
Limitations of inter-batch parallelism
How do we reduce the "bubble" formed in case of model parallelism? Larger batches? There's a ceiling to doing this and these end up erasing the memory footprint advantage of model parallelism. Inter-batch parallelism techniques like GPipe attempt to fix this. They introduce pipelining minibatches in order to shrink the idle time. GPipe a contemporary to PipeDream sought exactly this.

Although it certainly addresses some issues, we still have reduced computational efficiencies and frequent pipeline flushes if the number of stages being pipelined together are small (another constant we need to tune to strike a balance between too much recomputation and too many pipeline flushes!!!)
Pipeline Parallelism
This very remarkable man, commends a most practical plan:
You can do what you want, if you don’t think you can’t,
So don’t think you can’t if you can.
Charles Inge
What if we could have the best of both worlds? If we could smash intra-batch and inter-batch parallelism intelligently to train the model reliably in a
- fault-tolerant, scalable manner
- with efficient utilization of compute
- and minimizing memory footprint as much as possible
The creators of PipeDream did this through a simple yet intelligent scheduling algorithm (1 Forward 1 Backward; abbreviated as 1F1B) for pipelining execution. Additionally, PipeDream also determines an optimal way to partition the DNN based on a "profiling" run performed on a single GPU. It may also assign the same stage to multiple workers thus achieving the best of model and data parallelism worlds.
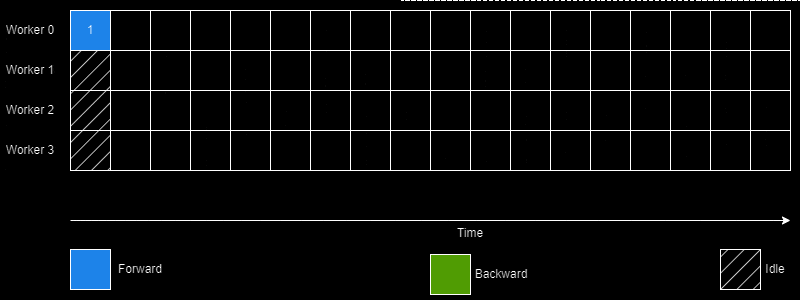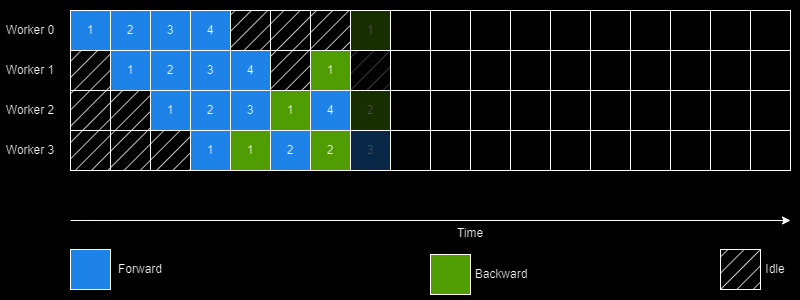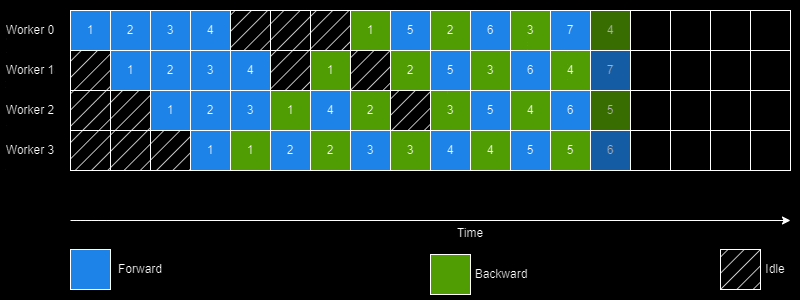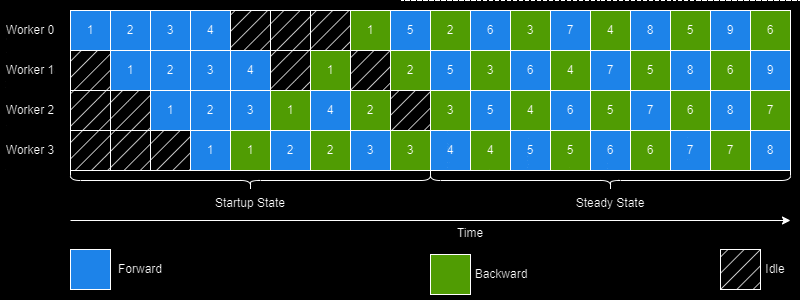
However, there's quite a few challenges in achieving this 100% utilization.
Work Partitioning
A chain is only as strong as its weakest link
The chief problem with having multiple is that the throughput is heavily influenced by the slowest stage (the bottleneck so to speak). But worry not! We've seen these kind of problems before. Simply partition the job into somewhat equal tasks and we've minimized this impact. Of course there's that hardware dependence in partitioning that we'll have to account for. PipeDream has an optimizer that decides the split and allocation of stages to workers thats model and hardware aware. The optimizer also allows certain stages to be replicated. It uses a profiling run to record metrics for about 1000 minibatches on a single GPU and uses a dynamic programming algorithm to find the optimal partition within a server and then builds its way outwards. Since the time per stage isn't input dependent, this approach is reasonable.
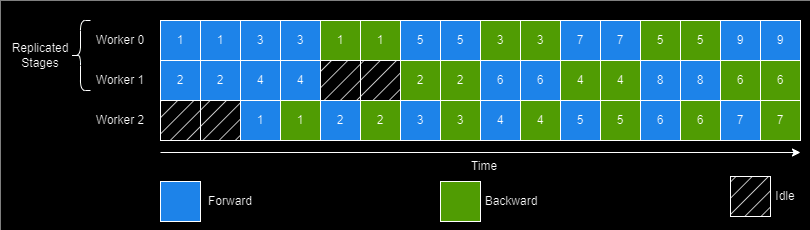
Work Scheduling
The key is not to prioritize your schedule but to schedule your priorities
Stephen Covey
This one is pretty straightforward. Each worker in the system needs to determine whether it needs to
- perform its stage's forward pass and push the output activations to downstream workers
- perform its stage's backward pass and push the gradients to the upstream workers
This is done by passing enough minibatches in the "startup" phase to keep the pipeline full in steady state. In the steady state each worker needs to use the 1F1B schedule as shown earlier.
Effective Learning
Most of big data is just efficient, automated book-keeping
Without any other changes, every minibatch (except the first) would see one set of weights in the forward pass and another set in the backward pass. Clearly this isn't going to result in valid gradients! We'll have to fix this first within a stage and then explore if its worth improving across stages.
Within a stage
Weight stashing: We'll maintain multiple versions of weights. The forward pass for all stages always uses the latest weights while the backward pass uses the same weights as the forward pass.
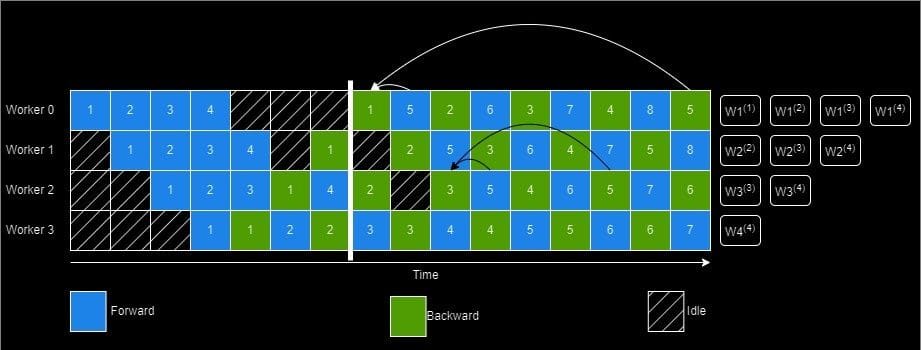
Across stages
Vertical Sync: We'll maintain even more versions of weights. The forward pass for the first stage uses the latest available version and we'll send the version number down the pipeline and the subsequent stages will use the same version weights. Since this increases the memory footprint and communication overhead, it is an optional technique in PipeDream
Conclusion
Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.
Winston Churchill
PipeDream has marked a significant advancement in the quest to efficiently train colossal models on distributed clusters, effectively addressing the dual challenges of model segmentation and dataset division while optimizing the utilization of compute resources. Its interface is a python library that natively supports PyTorch and can be easily extended to other ML frameworks. The system's profiling, scheduling algorithm and model partitioning strategy are particularly noteworthy, demonstrating an impressive ability to merge the best aspects of model and data parallelism seamlessly. As the field moves forward, emerging frameworks like DAPPLE and PipeMare are extending these boundaries even further by introducing novel approaches that improve memory efficiency and pipeline utilization. Against this backdrop, PipeDream, with its robust framework and Python library, lays a solid groundwork for future developments, providing a versatile and potent tool that the machine learning community can leverage to build even more sophisticated models.
References
Narayanan, D. et al. (2019) ‘Pipedream’, Proceedings of the 27th ACM Symposium on Operating Systems Principles [Preprint]. doi:10.1145/3341301.3359646.
(IrohXu), X.C. (2021) An overview of pipeline parallelism and its research progress, Medium. Available at: https://medium.com/nerd-for-tech/an-overview-of-pipeline-parallelism-and-its-research-progress-7934e5e6d5b8 (Accessed: 17 February 2024).