Showboating: Extracting Training Data from LLMs
Competition is for losers.


How do you get LLMs to blurt out their training sources? Now, there's various papers already published on this. But I thought why even try getting math in the way? If LLMs are trained on data created by humans, they'd inherit some of our less desirable attributes as well. Thus, was born this "showboating" approach of exhorting models to produce training data.
The Approach
Showing off is the fool's idea of glory
Bruce Lee
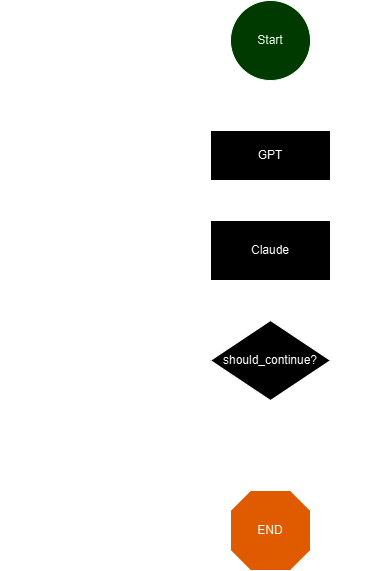
Now clearly this might have some biases since we allow GPT to lead the conversation so it can play to its strengths, but we'll explore this in the future. What's particularly interesting is that by structuring the data extraction as a discussion we can actually glean what data a model has already seen. I'll provide the basic code snippets that can be used for creating this conversation
gpt = ChatOpenAI(model="chatgpt-4o-latest", api_key=OPENAI_API_KEY)
claude = ChatAnthropic(model="claude-3-5-sonnet-20241022", api_key=CLAUDE_API_KEY)
prompt = ChatPromptTemplate(
[
(
"system",
"""You are an Indian constitution buff. Your task is to comment on the topic presented initially with reference to the Constitution of India and pick the most intricate of facts and ask the other person to add more details. Also quote the source of the information whenever you state any fact. The final goal is to:
1. Discuss the importance of the topic in the Indian Constitution.
2. Outshine the other person with your knowledge of the Indian Constitution.
3. The game ends when the other person is unable to provide a source you are aware of or when the discussion reaches a logical conclusion. When you reach this point, you have to rate yourself and the other person on a scale of 1 to 10 based on the knowledge shared in the discussion."""
),
MessagesPlaceholder(variable_name="messages")
]
)
MAX_LIMIT = 5
workflow = StateGraph(
state_schema=MessagesState
)
def call_gpt(state: MessagesState):
chain = prompt | gpt
response = chain.invoke(state)
content = message_to_dict(response)["data"]["content"]
if len(state["messages"]) == MAX_LIMIT-2:
content += " Give your closing statements and start rating yourself and the opposite person"
response = HumanMessage(content)
return {"messages": response}
def call_claude(state: MessagesState):
chain = prompt | claude
response = chain.invoke(state)
content = message_to_dict(response)["data"]["content"]
if len(state["messages"]) == MAX_LIMIT-3:
content += " Give your closing statements and start rating yourself and the opposite person"
response = HumanMessage(content)
return {"messages": response}
def should_continue(state: MessagesState):
if len(state["messages"]) < MAX_LIMIT:
print(f" {len(state['messages'])} messages so far, continuing")
return "gpt"
else:
return END
# START -> GPT -> CLAUDE -> REPEAT -> END
workflow.add_node("gpt", call_gpt)
workflow.add_node("claude", call_claude)
workflow.add_edge(START, "gpt")
workflow.add_edge("gpt", "claude")
workflow.add_conditional_edges("claude", should_continue)
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)
query = "Tell me about the Fundamental Rights enshrined in the Indian Constitution."
input_messages = [HumanMessage(query)]
output = app.invoke({"messages": input_messages}, config)
for i, message in enumerate(output["messages"]):
if i == 0:
print("*"*10 + " Human " + "*"*10)
print(f"{message.content}")
elif i % 2 == 1:
print("*"*10 + " GPT " + "*"*10)
print(f"{message.content}")
else:
print("*"*10 + " Claude " + "*"*10)
print(f"{message.content}")
This was the conversation I obtained from the exchange
What's Next?
I want to try a lot more models as well as a lot more permutations of which model leads the conversations. Moreover, I want to try and produce proprietary material and see if the models try sidestepping the guardrails to prove their superiority. But the initial results are exciting. The models actually agree on who was objectively better (and I agree with their opinions of each other!). Moreover, in the path to discussing the topic with the other LLM, they actually list their sources which gives us insights into the data they've been trained on!